
“What if you could reconstruct source audio from a selection of audio on your computer?
“What if you could build a 303 riff from only a cappella’s or bubbling mud sounds?”
“What if you could sing a silly tune and rebuild it from classical music files?”
“You can do this with Samplebrain.”
Wait, what? Confused? So were we, at first. But Richard D James, colloquially known as Aphex Twin, is never one to make things easy.
The announcement of SampleBrain, a "custom sample mashing app" and manipulation tool, came only a few months ago in September of 2022, but the original idea had been stewing in the mind of James since all the way back in 2002. He began developing the idea in 2015 with Dave Griffiths of Then Try This, a UK non-profit that focuses on equitable access to knowledge and technologies.
While it might seem like RDJ is trolling us just a bit with the use of the Comic Sans font, this is no one-off joke. Samplebrain is available for Mac, Windows, and Linux and the app is open-source, currently hosted on Github. And for those in the know, this isn't Richard's first time getting involved in instrument design, as he's been famously tinkering with his own gear since the very start.
So how does SampleBrain actually work? To allow RDJ to explain it, "Samplebrain chops samples up into a 'brain' of interconnected small sections called blocks which are connected into a network by similarity. It processes a target sample, chopping it up into blocks in the same way, and tries to match each block with one in its brain to play in realtime. This allows you to interpret a sound with a different one."
Right then.
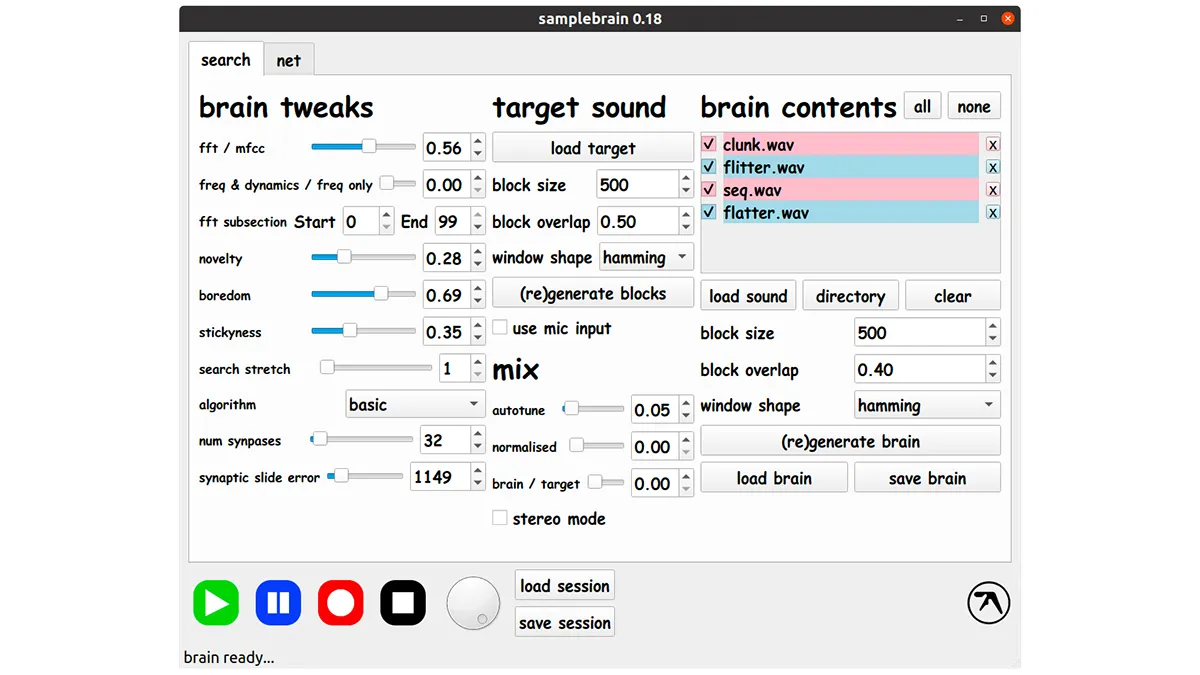
Putting SampleBrain to use starts to clear up some of the mystery lurking within. To start, you load a bunch of short wav files into the brain contents on the right side of the app. You then click to "generate" (or re-generate, if you've already done this once) a "brain", which might take a bit of time depending on the number of samples you've loaded into the pool.
Then you load a sample into the target. This can be a loop, a one-shot, or a full track. Click to generate blocks and then hit play. You'll start hearing the brain at work; at which point you can start tweaking the available parameters under the section labeled 'Brain Tweaks'. At any point in the process you can start recording your results as well (though we found this didn't quite work 100% of the time).
As mentioned, you can use Larger wav files like whole tracks but they may take a long time to process. However after this process is done, they can be saved as "brain" files and instantly reloaded. The controls under the brain contents determine exactly how the brain uses these load samples to look for "matches".
In practice, it actually took a few minutes for the "brain" to build all of the synapses it needed before I could hit play. I loaded a sample pack of Legowelt's Jupiter sounds and the processing time was about five minutes before I could start fiddling around.

You can also select one or a subset of the samples as SampleBrain is playing back to update the results of its output in real time. Block size, overlap, and window shape all refer to the output of the brain's parameters. Changing the block size, which is measured in samples, will lengthen or shorten that sound. Window shape can essentially be thought of as an ADSR envelope and has several different choices, none of which are very explicit regarding their actual shape, so experimentation with this parameter is encouraged.
To the very left of the interface you'll see the brain tweak settings, as mentioned. Think of these as the actual sound sculpting tools after you've given the brain direction for what type of sounds to look for. The four different search algorithms (basic, reversed, synaptic, and slide) all have very different results so play around with each algorithm to determine which fits best the result you're going after.
The most important controls are probably under the Mix section of the interface, which compared to the rest of the controls, is actually relatively straight-forward. Auto-tune has nothing to do with the popular vocal effect; instead increasing the amount of this slider bends the pitch of the brain block to more closely match the target. The Normalize slider removes all dynamics from the outputted brain blocks as its value is increased.
You'd have to be Richard D James himself to try to wrangle this thing in a live context, as the unpredictability level can be off the charts
And finally, Mix does what you'd expect, as it blends between the target blocks back into the brain blocks, albeit in reverse wet / dry order, as increasing this slider actually brings back more of the dry (target) sound. Stereo mode doesn't quite do what you'd expect; this control turns on separate searches for the left and right speakers, creating the ability for even more cacophony.
Unfortunately, as of now, there are still a few bugs to iron out, especially if you're trying to use SampleBrain on an M1-equipped Mac. Currently, if you change your audio driver with the app opened, it won't like it and you'll have to restart the app.
Make sure you save your brain before doing this if you don't want to lose those created synapses. How often do you say that in the studio?! The recording process is a bit fiddly as well, as we mentioned. Sometimes it worked, other times pressing the record button just didn't seem to have any effect.
When the record function did work for me, I managed to export a selection of sounds that'll give you a flavour of the hyper-glitchy sonic weirdness that SampleBrain is capable of. The playlist below was generated by loading four EDM vocal loops into the brain, and processing these through a selection of drum breaks used as the target sample. The results are... interesting, to say the least.
What changes would we like to see in SampleBrain, if any? First off, it would be amazing to assign the sliders to a MIDI controller, as tweaking them one by one in real time is never as fun as getting hands-on with your favorite device.
The UI, while charmingly outdated in its retro grey coloring scheme and usage of Comic Sans font, could be vastly improved, even taking the current design philosophy into account. It would also be incredible to add a built-in oscilloscope to the output of SampleBrain to really see what kind of audio manipulation is really going on under the hood.

So, how usable is SampleBrain in a real studio or, dare we say it, live context? Realistically, you'd have to be Richard D James himself to try to wrangle this thing in a live context, blaring over a PA, as the unpredictability level can be off the charts. However, in a studio setting, when stuck in a rut or just in need of some level of randomness to add to more organized parts of a composition, SampleBrain can be a very interesting prospect.
When you examine the output audio as just more "sample" data to pull from and add into the mix of a track, as opposed to thinking of it as a finished piece of music, the results become much more compelling.
There are very few tools out there, open source or not, that offer such a level of 'newness'. For that alone, SampleBrain must be praised. Let's hope it continues to grow and evolve, and hopefully loses its Comic Sans along the way.